


Le projet
Ce projet porte sur l’analyse automatique de discours, en cherchant à déplacer des méthodes développées jusqu’à présent pour l’analyse du discours et du témoignage dans les textes littéraires sur des textes jugés a priori non littéraires. Il propose que dans l’étude globale d’un corpus de textes émanant de praticiens de la médecine (médecins, soignants, étudiants), qui peut faire l’objet d’une analyse statistique, soient pris en compte le récit, son énonciation, l’émotion et le temps. Il se situe donc bien au croisement des humanitésmédicales et des humanitésnumériques. Il s’inscrit donc dans le contexte large du Life course analysis : l’analyse des parcours de vie qui a pénétré les sciences sociales depuis le début des années 2000. Il se décline en deux volets :
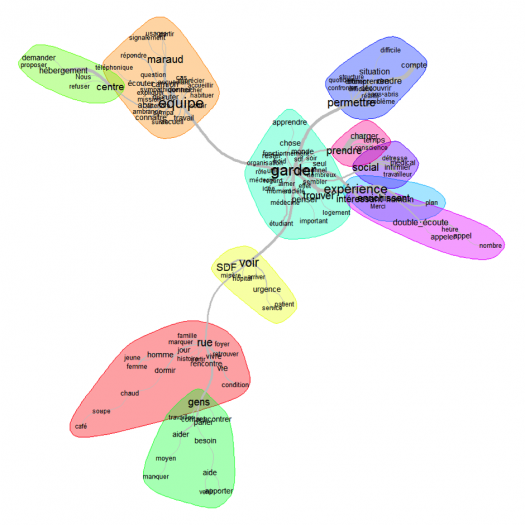
L’étude d’un premier corpus contemporain, composé de près de 3500 rapports rédigés par les étudiants en médecine après une expérience auprès du SAMU Social, sera l’occasion de développer une méthode de fouille sémantique adaptée à ce type de discours. Un système d’annotations à base de règles pourra être élaboré de manière à identifier et à catégoriser au sein du corpus les différents types de vécus (descriptif, émotionnel, sensoriel, positif / négatif…). À plus long terme, un tel travail aboutira au développement d’une interface, proposant une exploration des textes selon la nature de l’expérience et les affects engagés. Notre méthode aura l’avantage d’être réutilisable sur des corpus contemporains de plus large ampleur, tels que les réseaux sociaux médicaux.
Ce premier volet du projet est envisagé de manière à servir parallèlement le traitement d’un corpus patrimonial inédit constitué à partir du fonds historique Charcot, détenu par la Jubilothèque de la Faculté des Sciences de Sorbonne Université. En vue de leur exploration, ces documents d’archives feront tout d’abord l’objet d’une numérisation complète, puis d’une analyse statistique et sémantique à partir de notre méthode d’exploration.
Les membres
Sorbonne Université
Sorbonne Université
Sorbonne Université
Sorbonne Université
